임베딩 전반적으로 이해하기
by 이정윤
🌊 Introduction
자연어처리 단계 중, 지금까지 전처리(Preprocessing)과 형태소 분석(Tokenization)에 대해서 공부하고 실습을 진행했다. 지금부터는 자연어를 컴퓨터가 인식하고 처리할 수 있는 형태로 바꾸는 임베딩에 대하여 알아보도록 하겠다.
임베딩 이란 자연어를 컴퓨터가 처리할 수 있도록 숫자들의 나열인 벡터, 즉 0과 1로 바꾸는 것을 의미한다. 지금도 꾸준히 발전된 새로운 모델들이 등장하는만큼, 임베딩의 방법과 종류는 굉장히 다양하다. 인터넷과 도서에 이미 정리되어 있는 자료가 많긴 하지만, 분류 기준의 차이인지 다루는 범위의 차이인지, 존재하는 자료들로는 임베딩 기법의 전체적인 틀을 이해하기 다소 어려운 부분이 있었다. 따라서 여러 자료들을 종합하여 한 번 쯤 들어보긴 했지만 어떤 기법에 속하는지, 어떤 원리를 사용한 것인지 등 전반적인 기법들의 개념을 정리해보는 시간을 가져보려고 한다. 언제나처럼 실습이 이 스터디의 주목표이므로 깊은 내용까지 들어가진 않는다.
여러 자료를 많이 참고했지만, 종합하여 이해하는 과정에서 오류가 발생했을 수 있다. 내용상 오류 정정은 언제나 감사한 마음으로 환영한다. (cathx618@gmail.com)
참고도서: 한국어임베딩(이기창, 2019)
참고자료: 인공지능과 자연어 처리 기술 동향 (유승의, 정보통신기획평가원, 2021.2.17)
🌊 Before We Start
앞서 언급했듯, 임베딩이란 사람의 말인 자연어를 컴퓨터가 이해, 즉 계산할 수 있도록 숫자형태로 바꾸는 것이다. 임베딩을 통해서 수행할 수 있는 역할은 다음과 같다.
- 단어, 문장간의 관련도 계산
- 단어와 단어, 문장과 문장간의 관련도(유사도)를 수치로 계산 가능.
- 의미적, 문법적 정보 함축
- 단어와 단어 사이의 의미적, 문법적 관계를 수치로 도출 가능.
- 전이학습
- 임베딩 결과를 다른 딥러닝 모델의 입력값으로 사용 가능.
- 의미적, 문법적 정보가 담긴 수치들을 입력값으로 사용하여 딥러닝 알고리즘 성능이 더욱 향상될 수 있음.
- 그러나 특정한 목적을 가진 딥러닝 모델에 사전 훈련된 임베딩 벡터 입력값들이 적합하지 않을 수 있다. 이와 관련된 추가적인 내용은 NLP with PyTorch - 전이학습 이 사이트를 참고하면 좋을 것 같다.
그렇다면, 단어를 어떤 기준과 방식을 통해 의미있는 수치정보로 표현할 수 있을까? 임베딩을 만드는 세 가지 철학은 다음과 같다. (출처: 한국어 임베딩(이기창, 2019), p58~77)
| 백오브워즈 가정 | 언어모델 | 분포가정 | |
|---|---|---|---|
| 내용 | 단어의 출현빈도 (어떤 단어가 많이 쓰였는가) | 단어의 순서 (단어가 어떤 순서로 쓰였는가) | 단어의 분포 (어떤 단어가 같이 쓰였는가) |
| 대표 통계량 | TF-IDF | - | PMI(점별 상호 정보량) |
| 대표 모델 | Deep Averaging Network | ELMo, GPT | Word2Vec |
사실 이 표의 의미에 대해서 완벽하게 이해하진 못했다. 다만, 이 세가지 요소들은 서로를 포함하는 관계도 되기 때문에 완전하게 경계를 나눠서 인식하면 안된다고 이해했다. (아래 내용을 보면 이 말이 이해갈 것!)
단어의 출현빈도는 단순하게 어떤 단어가 빈번하게 등장하는 지를 고려한다. 따라서 문장 내에서 단어의 순서나 문맥적을 반영하진 않는다. TF-IDF는 고려한다는 점에서 단순한 빈도 카운트는 아니지만, 여전히 빈도에 큰 중점을 두기 때문에 BoW (Bag of Words) 기법에 속한다.
반면, 단어의 순서는 말 그대로 단어 문장 속에서 사용된 순서, 즉 시퀀스를 고려한다. 이때 '언어모델' 이라는 개념이 등장하는데, 언어모델이란 단어 시퀀스에 확률을 부여하는 모델이다. (한국어 임베딩, 이기창, 2019, p64) 이 언어모델은 다시 '통계적 기반 언어모델'과 '뉴럴 네트워크(신경망) 기반 언어모델'로 구분할 수 있다.
마지막으로 단어의 분포는 문맥을 고려하는 방법이다. 즉, 비슷한 문맥환경에서 특정 쌍이 자주 등장한다면, 그 의미도 유사할 것이라는 가정에서 기반한다.
한편, 언어모델 부분에 대한 이해가 어려웠다. 앞서 구분한 언어모델 중 통계적 기반 언어모델에는 n개를 고려한 카운트 기반인 n-gram이 있다. 여기서 드는 의문은 n-gram 역시 카운트 기반인데, 언어모델은 단어의 시쿼스를 기반으로 확률을 부여하다는 설명 때문이었다. 처음에 언급했듯, 세 요소들을 뚜렷한 경계를 두고 이해하면 안될 것 같다. 즉, 단어의 순서를 고려했다고 해서 단어의 빈도를 고려하지 않은 것은 아니라는 것!
이를 더 쉽게 이해하기 위해 통계적 언어모델 (SLM)에 대해서 조금 더 자세히 알아보자.
- 문장에 대한 확률 (조건부 확률 기반)
조건부 확률을 연쇄법직을 문장에 적용하는 것인데, 수식으로 설명하는 것보다 아래 예시가 이해하기 더 쉬울 것 같다.
P(나는 자연어 처리 공부를 합니다)= P(나는) X P(자연어|나는) X P(처리|나는 자연어) X P(공부를|나는 자연어 처리) X P(합니다|나는 자연어 처리 공부를) - 카운트 기반의 접근
위 예시의 수식에서 각각의 단어에 대한 확률을 계산할 때 바로 카운트 기반으로 접근한다는 것이다. 예를 들어 '나는 자연어 처리'라는 구가 등장한 횟수를 세고, '나는 자연어 처리 공부를'이라는 구가 등장한 횟수를 셌을 때, 전자가 100번, 후자가 20번이면 P(공부를|나는 자연어 처리)는 20%이다.
이 계산법의 한계는 충분한 양의 말뭉치(corpus)가 준비되지 않는다면, 제대로된 학습이 이루어지지 않는다는 것이다.
P(공부를|나는 자연어 처리)=COUNT(나는 자연어 처리 공부를)/COUNT(나는 자연어 처리)
참고 사이트: 임베딩의 역할, Natural Language Processing with PyTorch, 위키북스-통계적 언어모델, Language Model(언어 모델)
🌊 Embedding
내가 이해한 내용들을 한 페이지로 정리하면 다음 표와 같다. 간단해보이지만, 이 정리를 하기까지 꽤 많은 노력과 공부가 필요했다. 여러 의견이 다른 자료들을 참고하였기 때문에 일부 기법의 카테고리 분류가 애매할 수 있지만, 현재까지 이해를 바탕으로 분류한 것이며 추후 수정될 수 있다. 대략적인 내용에 대한 간단한 설명은 아래에 있고, 세부적인 이해는 다음 스터디에서 진행하도록 하겠다.
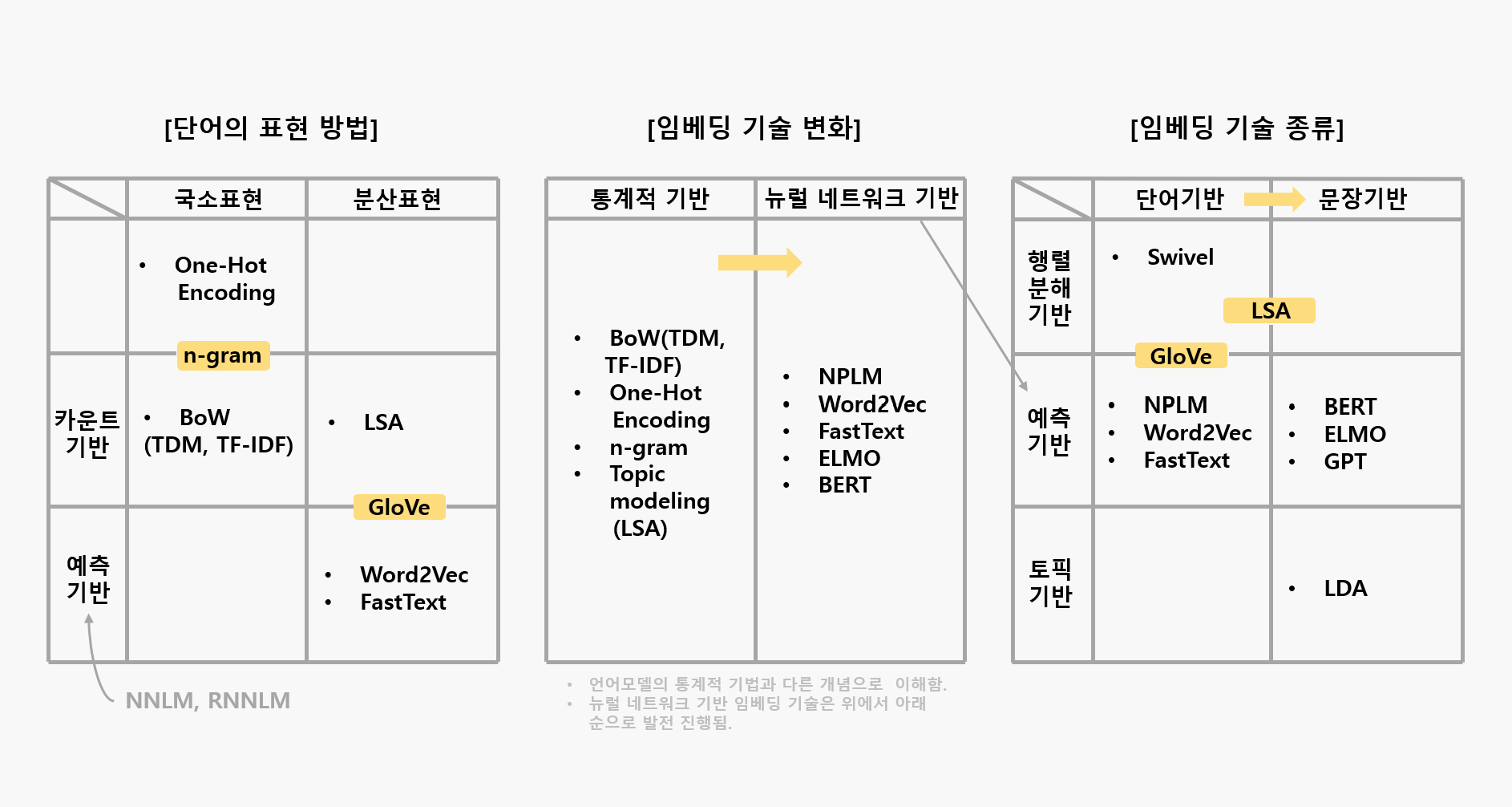
참고사이트: 임베딩의 역할, 임베딩 기술 흐름과 종류, 위키독스-다양한 단어의 표현방법
1. 단어의 표현방법
- 국소표현 (Local Representation = 이산표현 Discrete Representation)
- 해당 단어 자체만 보고 특정값을 맵핑하여 표현하는 방법.
- 무더운 여름 -> '무더운' 과 '여름'을 각각 따로 인식하여 숫자 부여함.
- 분산표현 (Distributed Representation= 연속표현 Continuous Representation)
- 표현한 단어 주변을 참고하여 표현하는 방법
- 무더운 여름 -> 여름 주변에 '무더운'이라는 단어가 많다면 그 단어를 '여름'을 표현하는 단어로 정의함.
- 단어의 뉘앙스를 표현할 수 있는 방법
- 연속표현을 분산표현을 포괄하고 있는 더 큰 개념으로 설명하기도 함. (참고)
'위키독스-다양한 단어의 표현방법'의 내용을 참고하였는데, NNLM과 RNNLM은 해당 개념에 대해 정확히 알지 못해 국소표현, 분산표현 중에 구분하지 않았다.
2. 임베딩 기술
- 통계적 기반
이때의 통계적 기반은 '통계적 기반 언어모델'과 100% 동일한 개념으로 이해하진 않았다. (카운트 기반과 의미상 더 가깝다고 생각했지만, 이역시 동일한 개념은 아닌 듯) * Topic modeling: 토필 모델링의 일종인 LSA(Latent, Senantic Analysis, 잠재의미분석)은 행렬분해 기반 기법으로 BoW, TF-IDF 처럼 빈도수만 고려할 때와 달리 행간의 잠재 의미를 이끌어내기 위한 방법이다. 데이터 차원의 수를 줄여 계산 효율성을 키우기도 한다. (행렬분해 기법) LSA의 단점을 보완한 것이 LDA (Latent Dirichlet Allocation, 잠재 디리클레 할당)이다.
- 뉴럴 네트워크 기반
이전의 단어들이 주어졌을 때, 다음에 어떤 단어가 나올지 예측하거나 문장 내 일부분에 구멍을 뚫어놓고 해당 단어가 무엇일지 맞추는 과정에서 학습을 하는 기법을 말한다. (한국어 임베딩, p38) * Word2Vec, FastText는 단어기반 임베딩, ELMo, BERT는 문장기반 임베딩에 속함.
참고도서: 한국어임베딩(이기창, 2019)
참고사이트: 위키독스-잠재 의미 분석, 토픽 모델링-잠재의미분석
3. 임베딩 기술 종류
임베딩 기술은 초기에는 단어기반의 임베딩(NLPM, Word2Vec, GloVe, FastText, Swivel 등)을 진행했지만, 최근에는 문장기반 임베딩(ELMo, BERT, GPT 등)이 주목받고 있다. 단어기반 임베딩은 동음이의어를 구분하기 어려운 반면, 문서기반 임베딩은 이를 구분할 수 있다. LSA는 차원 축소를 한 행렬을 기존 행렬과 비교할 때 단어를 기준으로 하면 단어 단어기반 임베딩, 문서를 기준으로 하면 문서기반 임베딩이 된다.
- 행렬분해 기반
- 말뭉치(corpus) 정보가 들어 있는 원래 행렬을 두개 이상의 작은 행렬로 쪼개는 방식.
- 예측기반
- 특정 단어 다음, 문장 중간에 어떤 단어가 나타날지 맞추는 과정에서 학습하는 방식.
- 뉴럴 네트워크 기반 기법들이 예측기반에 속함.
- 토픽기반
- 주어진 문서에 잠재된 주제를 추론하는 방식.
- 학습 뒤 확률벡터로 반환하므로 임베당 기법의 일종으로 이해함.
참고도서: 한국어임베딩(이기창, 2019)
🌊 Future tasks
이번 스터디에서는 본격적인 임베딩 실습에 들어가기 앞서 임베딩에 대한 기본적인 개념 정리를 했다. 임베딩 기술 종류 분류에서 등장한 기술들에 대한 모든 기술들 하나하나 세부적으로 들어가면 굉장히 방대하고 어려운 내용들이 나오므로 전부를 이해할 필요는 없을 듯 하여 기초적인 부분만 이해하고 넘어가도록 하겠다. 실제로 실습을 진행해볼 기술에 대해서는 다음 스터디에서 더 자세히 다뤄볼 예정이다.
다음에는 본격적으로 임베딩 실습을 진행하고자 한다.
- 단어기반 임베딩
- Word2Vec
- GloVe